本文章参考学习项目:https://github.com/bbruceyuan/LLMs-Zero-to-Hero
简单来说,我们在做一件“自己造轮子”的事:不依赖现成的深度学习库(如HuggingFace Transformers),仅使用PyTorch的基础组件,从零实现一个简化版的GPT模型,并用它来训练和生成文本 。
总体思路如下 :
第一步:定义蓝图(配置) 代码开头的GPTConfig类定义了模型的“超参数”,比如有多少层(n_layer)、多少个头(n_head)、嵌入维度(n_embd)等。这就像一个建筑图纸,规定了积木的大小和形状。
第二步:搭建基础积木(核心组件) 从最核心的“单头注意力机制”(SingleHeadAttention)开始写。这里手动实现了Q、K、V的线性变换,以及因果掩码(causal mask) ,确保模型只能看到当前位置之前的信息,这是GPT模型能够做预测的关键。MultiHeadAttention)。这就像是把多个单头注意力拼在一起,让模型能从不同角度理解文本。
创建了FeedForward(即MLP)和Block类。一个标准的Transformer块就是将“注意力层”和“前馈层”串起来,中间加上残差连接和层归一化。这是GPT的核心处理单元。
第四步:组装最终产品(完整GPT模型) 用GPT类将所有积木组装起来。它包含了词嵌入和位置嵌入,然后堆叠多个Block,最后通过一个线性层(lm_head)将隐藏状态映射回词表大小,输出每个位置的下一个词的概率。
第五步:准备“原材料”(数据处理) MyDataset类负责读取数据。它读取JSONL文件,使用tiktoken将文本转换为数字(token ID),然后将长文本分割成固定长度(block_size)的片段。每个片段的前block_size个token作为输入(x),后block_size个token作为目标输出(y),用于计算损失。
第六步:让模型动起来(训练与生成) 最后,代码构建了DataLoader,定义了优化器和学习率调度器,并编写了train和eval函数。在训练循环中,它进行前向传播、计算损失、反向传播和参数更新,并定期保存模型检查点。
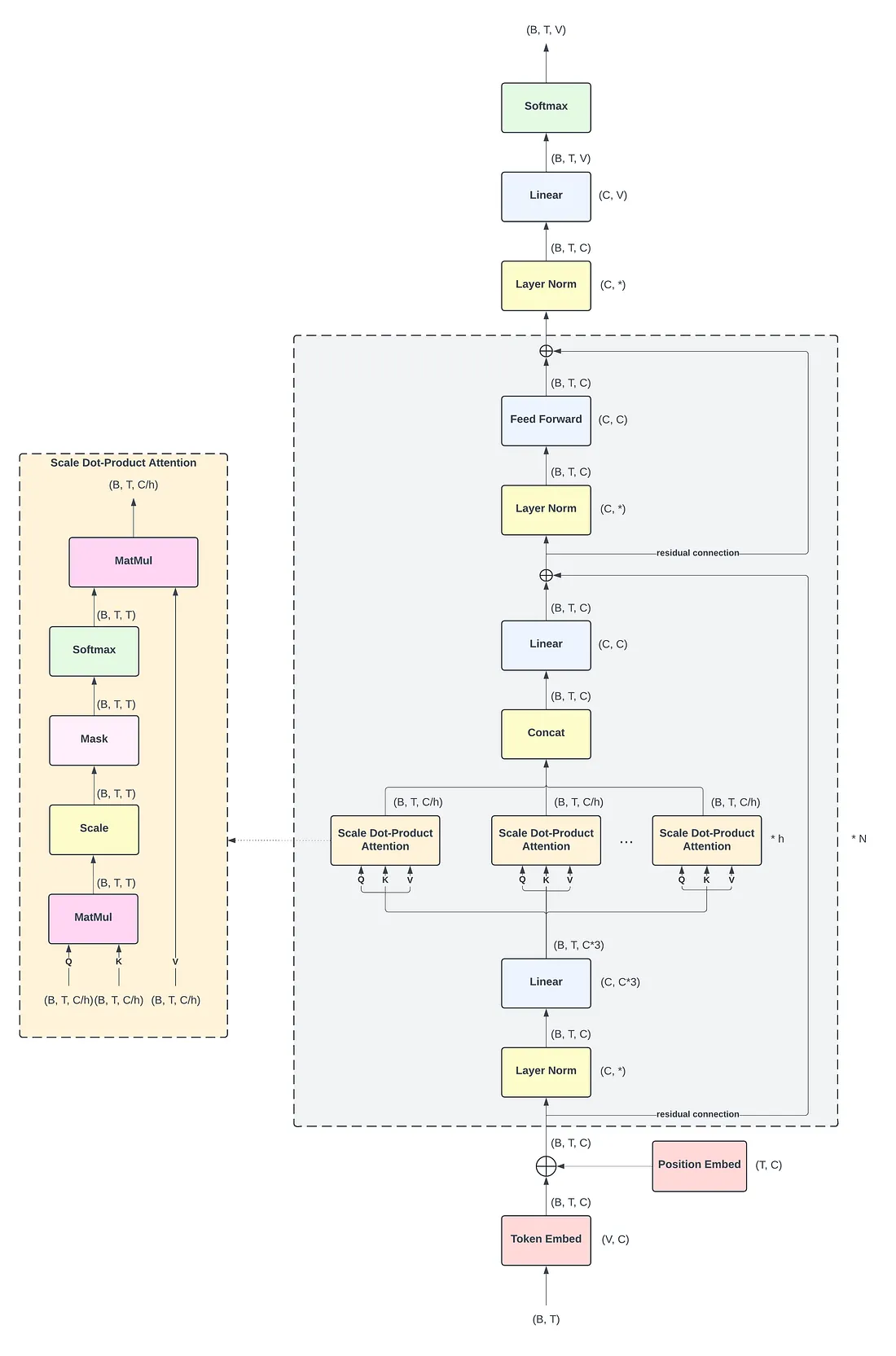
要理解GPT的核心思路,这里可以参考GPT-2的详细模型架构。
在学习的过程中,非常建议看3Blue1Brown的这个视频辅助理解,常看常新:https://www.bilibili.com/video/BV13z421U7cs https://www.bilibili.com/video/BV1TZ421j7Ke
输入是一个序列 :假设一次输入 B 条句子(batch size),每条句子长度是 T(token数)。所以输入的形状是 (B, T),里面存的是每个 token 的 ID。Token Embedding :用一个查找表把每个 token ID 变成对应的词向量。词向量的维度是 C(即模型隐藏层大小),所以这一步输出 (B, T, C)。Position Embedding :因为 Transformer 没有“顺序感”,需要额外告诉模型每个 token 在序列中的位置。这里也用一个可学习的查找表,根据位置索引得到位置向量,形状也是 (T, C)。两者直接相加 ,得到带位置信息的输入表示,形状 (B, T, C)。
讲解一下:
B = Batch Size(批次大小):一次同时喂给模型多少句话。主要处理并行计算加速。
T = Sequence Length(序列长度):一句话里有多少个 token(词 / 字)。
C = Hidden Size(隐藏层大小):每个词用多少维向量表示。一般来说,C越大,维度越高,一个词的含义越丰富,能捕捉更丰富的语义(情感、逻辑、上下文),但模型更大更慢。
举个例子:
1 2 3 4 5 6 假设: B = 8(一次处理 8 句话) T = 100(每句话最长 100 个词) C = 768 那么输入形状就是: (8, 100, 768)
图上画了一个 N 的标记,表示这个块会堆叠 N 次(比如 GPT‑2 的 12、24 层)。每个块内部结构完全相同,让我们仔细看。
输入先过一个 LayerNorm ,保证数值稳定,加速训练。
之后进入 多头自注意力(Multi‑Head Attention) 。
这是 GPT 最关键的部分。
线性变换 :输入经过三个不同的线性层,分别得到 Q(查询)、K(键)、V(值) 。它们的形状都是 (B, T, C)。分头 :把 C 维拆成 h 个头,每个头的维度是 C/h(图中写的 C/h)。所以 Q、K、V 就变成了 (B, h, T, C/h)。缩放点积注意力 :
计算 Q @ K^T,得到 (B, h, T, T) 的注意力分数。
除以 sqrt(C/h) 进行缩放,防止梯度消失。
Mask :因为 GPT 是自回归的,生成当前词时不能看到未来的词。所以会用一个“上三角”掩码把未来位置的分数变成负无穷,这样 softmax 后它们的权重几乎为零。对注意力分数做 softmax,再乘上 V,得到每个头的输出 (B, h, T, C/h)。
拼接与投影 :把 h 个头的结果在最后一个维度拼起来,变回 (B, T, C),再经过一个线性层(图中标注的 Linear (C, C))进行混合。这一步输出就是注意力模块的结果。
讲解一下: Q和K决定注意力在哪里(关联的程度、权重),V将相关的内容融合进来
Output = Softmax ( Q K ⊤ d ) ⋅ V \text{Output} = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d}}\right) \cdot V
Output = Softmax ( d Q K ⊤ ) ⋅ V
如果缺少Q和V,就会变成简单的平均:
Output = 1 T ∑ V i \text{Output} = \frac{1}{T}\sum V_i
Output = T 1 ∑ V i
多头注意力机制,就是C/h,提高模型对上下文的理解,以及并行计算的速度。
具体地,W Q W_Q W Q W Q W_Q W Q W Q W_Q W Q
W Q W_Q W Q 训练开始前,没人知道 W Q W_Q W Q
W Q = [ 0.1 0.2 0.3 0.4 ] W_Q = \begin{bmatrix}
0.1 & 0.2 \\
0.3 & 0.4
\end{bmatrix}
W Q = [ 0 . 1 0 . 3 0 . 2 0 . 4 ]
这些数字完全是乱的 ,模型此时啥也不会。
W Q W_Q W Q 输入词向量:
x = [ 0.5 , 0.3 ] x = [0.5,\ 0.3]
x = [ 0 . 5 , 0 . 3 ]
计算 Q:
Q = x ⋅ W Q = [ 0.5 , 0.3 ] [ 0.1 0.2 0.3 0.4 ] = [ 0.14 , 0.22 ] Q = x \cdot W_Q
= [0.5,\ 0.3] \begin{bmatrix}0.1&0.2\\0.3&0.4\end{bmatrix}
= [0.14,\ 0.22]
Q = x ⋅ W Q = [ 0 . 5 , 0 . 3 ] [ 0 . 1 0 . 3 0 . 2 0 . 4 ] = [ 0 . 1 4 , 0 . 2 2 ]
同理算出 K、V,再算注意力,最后得到模型输出。
假设这是一个语言模型:
就会产生一个 loss 值 ,比如 loss = 2.7
这个 loss 代表:模型错得有多离谱
W Q W_Q W Q 这是训练最关键的一步。
神经网络会自动求导:
∂ l o s s ∂ W Q \frac{\partial loss}{\partial W_Q}
∂ W Q ∂ l o s s
也就是:W Q W_Q W Q
比如算出来梯度可能是:
∇ W Q = [ 0.02 − 0.01 0.03 − 0.02 ] \nabla W_Q = \begin{bmatrix}
0.02 & -0.01 \\
0.03 & -0.02
\end{bmatrix}
∇ W Q = [ 0 . 0 2 0 . 0 3 − 0 . 0 1 − 0 . 0 2 ]
梯度的意义:
正数:这个值变大,loss 会变大
负数:这个值变大,loss 会变小
W Q W_Q W Q 用梯度下降公式:
W Q new = W Q old − l r × ∇ W Q W_Q^{\text{new}} = W_Q^{\text{old}} - lr \times \nabla W_Q
W Q new = W Q old − l r × ∇ W Q
lr 是学习率,比如 0.01。
更新第一个值:
0.1 − 0.01 × 0.02 = 0.0998 0.1 - 0.01\times0.02 = 0.0998
0 . 1 − 0 . 0 1 × 0 . 0 2 = 0 . 0 9 9 8
全部更新后,新的 W_Q 变成:
W Q new = [ 0.0998 0.2001 0.2997 0.4002 ] W_Q^{\text{new}} = \begin{bmatrix}
0.0998 & 0.2001 \\
0.2997 & 0.4002
\end{bmatrix}
W Q new = [ 0 . 0 9 9 8 0 . 2 9 9 7 0 . 2 0 0 1 0 . 4 0 0 2 ]
此时只变了一丢丢,几乎看不出来。
前向算 Q
算 loss
反向算梯度
更新 W_Q
慢慢的,同理Q、K、V:
W_Q 越来越擅长把 x 变成好用的查询向量
W_K 越来越擅长变成匹配用的键
W_V 越来越擅长变成信息载体
堆叠完 N 个块之后,再经过一个 Layer Norm (图中“Layer Norm (C, *)”)。
然后是一个线性层 Linear (C, V) ,把隐藏状态 (B, T, C) 映射到词表大小 V,得到每个位置上每个词的得分(logits),形状 (B, T, V)。
最后用 Softmax 把得分转换成概率分布(图中 Softmax)。训练时用交叉熵计算损失,生成时则从这个分布里采样下一个词。
这里再补充一下softmax:
Softmax ( x i ) = e x i ∑ j = 1 N e x j \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{N} e^{x_j}}
Softmax ( x i ) = ∑ j = 1 N e x j e x i
就是一个常见的归一化方法。
Softmax ( x i , τ ) = e x i / τ ∑ j = 1 N e x j / τ \text{Softmax}(x_i, \tau) = \frac{e^{x_i / \tau}}{\sum_{j=1}^{N} e^{x_j / \tau}}
Softmax ( x i , τ ) = ∑ j = 1 N e x j / τ e x i / τ
整个注意力机制:
Output = Softmax ( Q K ⊤ d ) ⋅ V \text{Output} = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d}}\right) \cdot V
Output = Softmax ( d Q K ⊤ ) ⋅ V
注意 :在 self-attention 计算中,注意力权重是通过 Query 和 Key 的点积得到的。点积的值随着向量维度 d k d_k d k score = Q ⋅ K T \text{score} = Q \cdot K^T score = Q ⋅ K T score \text{score} score 梯度消失 或梯度饱和 的问题。因为 softmax 在输入非常大或非常小时,会趋向于“接近 0 或 1”,对梯度的敏感性下降,从而影响模型训练。为了防止 softmax 输出过于极端、保持数值稳定性,需要对 score \text{score} score d k \sqrt{d_k} d k score \text{score} score
基本上这个代码的含义以及是干什么的,我都在后面有注释或者解释。
1 2 3 4 5 6 7 8 9 10 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import Datasetfrom torch.utils.data import DataLoaderfrom dataclasses import dataclassimport mathtorch.manual_seed(1024 )
1 2 3 4 5 6 7 8 9 10 11 12 13 @dataclass class GPTConfig : block_size: int = 512 batch_size: int = 12 n_layer: int = 6 n_head: int = 12 n_embd: int = 768 head_size: int = n_embd // n_head dropout: float = 0.1 vocab_size: int = 50257
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class SingleHeadAttention (nn.Module): def __init__ (self, config ): super ().__init__() self .key = nn.Linear(config.n_embd, config.head_size) self .value = nn.Linear(config.n_embd, config.head_size) self .query = nn.Linear(config.n_embd, config.head_size) self .head_size = config.head_size self .register_buffer( 'attention_mask' , torch.tril(torch.ones(config.block_size, config.block_size)) ) self .dropout = nn.Dropout(config.dropout) def forward (self, x ): batch_size, seq_len, hidden_size = x.size() k = self .key(x) v = self .value(x) q = self .query(x) weight = q @ k.transpose(-2 , -1 ) weight = weight.masked_fill( self .attention_mask[:seq_len, :seq_len] == 0 , float ('-inf' ) ) / math.sqrt(self .head_size) weight = F.softmax(weight, dim=-1 ) weight = self .dropout(weight) out = weight @ v return out
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class MultiHeadAttention (nn.Module): def __init__ (self, config ): super ().__init__() self .heads = nn.ModuleList( [ SingleHeadAttention(config) for _ in range (config.n_head) ] ) self .proj = nn.Linear(config.n_embd, config.n_embd) self .dropout = nn.Dropout(config.dropout) def forward (self, x ): output = torch.cat( [h(x) for h in self .heads], dim=-1 ) output = self .proj(output) output = self .dropout(output) return output
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class FeedForward (nn.Module): def __init__ (self, config ): super ().__init__() self .net = nn.Sequential( nn.Linear(config.n_embd, 4 * config.n_embd), nn.GELU(), nn.Linear(4 * config.n_embd, config.n_embd), nn.Dropout(config.dropout) ) def forward (self, x ): return self .net(x)
Attention = 大家互相聊天、找关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Block (nn.Module): def __init__ (self, config ): super ().__init__() head_size = config.n_embd // config.n_head self .att = MultiHeadAttention(config) self .ffn = FeedForward(config) self .ln1 = nn.LayerNorm(config.n_embd) self .ln2 = nn.LayerNorm(config.n_embd) def forward (self, x ): x = x + self .att(self .ln1(x)) x = x + self .ffn(self .ln2(x)) return x
先记住一句话举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 输入一句话 x ↓ ln1 标准化 ↓ att 注意力:词之间互相找关系 ↓ 残差:加上原来的 x(保留原味) → 得到新 x ↓ ln2 标准化 ↓ ffn 前馈:每个词自己深度思考 ↓ 残差:加上刚才的 x(保留记忆) ↓ 输出最终结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 class GPT (nn.Module): def __init__ (self, config ): super ().__init__() self .token_embedding_table = nn.Embedding(config.vocab_size, config.n_embd) self .position_embedding_table = nn.Embedding(config.block_size, config.n_embd) self .blocks = nn.Sequential( *[Block(config) for _ in range (config.n_layer)] ) self .ln_final = nn.LayerNorm(config.n_embd) self .lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False ) self .apply(self ._init_weights) def _init_weights (self, module ): if isinstance (module, nn.Linear): torch.nn.init.normal_(module.weight, mean=0.0 , std=0.02 ) if module.bias is not None : torch.nn.init.zeros_(module.bias) elif isinstance (module, nn.Embedding): torch.nn.init.normal_(module.weight, mean=0.0 , std=0.02 ) def forward (self, idx, targets=None ): batch, seq_len = idx.size() token_emb = self .token_embedding_table(idx) pos_emb = self .position_embedding_table( torch.arange(seq_len, device=idx.device) ) x = token_emb + pos_emb x = self .blocks(x) x = self .ln_final(x) logits = self .lm_head(x) if targets is None : loss = None else : batch, seq_len, vocab_size = logits.size() logits = logits.view(batch * seq_len, vocab_size) targets = targets.view(batch * seq_len) loss = F.cross_entropy(logits, targets) return logits, loss def generate (self, idx, max_new_tokens ): for _ in range (max_new_tokens): idx_cond = idx if idx.size(1 ) <= self .block_size else idx[:, -self .block_size:] logits, _ = self (idx_cond) logits = logits[:, -1 , :] probs = F.softmax(logits, dim=-1 ) idx_next = torch.multinomial(probs, num_samples=1 ) idx = torch.cat((idx, idx_next), dim=1 ) return idx
把文字切成模型能吃的小块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class MyDataset (Dataset ): def __init__ (self, path, block_size=512 ): import tiktoken self .enc = tiktoken.get_encoding("gpt2" ) self .block_size = block_size self .eos_token = self .enc.encode( "<|endoftext|>" , allowed_special={"<|endoftext|>" } )[0 ] import json self .encoded_data = [] self .max_lines = 1000 raw_data = [] with open (path, 'r' ) as f: for i, line in enumerate (f): if i >= self .max_lines: break try : text = json.loads(line.strip())['text' ] raw_data.append(text) except json.JSONDecodeError: continue except Exception as e: continue full_encoded = [] for text in raw_data: encoded_text = self .enc.encode(text) full_encoded.extend(encoded_text + [self .eos_token]) for i in range (0 , len (full_encoded), self .block_size): chunk = full_encoded[i:i+self .block_size+1 ] if len (chunk) < self .block_size + 1 : chunk = chunk + [self .eos_token] * (self .block_size + 1 - len (chunk)) self .encoded_data.append(chunk) def __len__ (self ): return len (self .encoded_data) def __getitem__ (self, idx ): chunk = self .encoded_data[idx] x = torch.tensor(chunk[:-1 ], dtype=torch.long) y = torch.tensor(chunk[1 :], dtype=torch.long) return x, y def encode (self, text ): """将文本编码为token IDs""" return self .enc.encode(text) def decode (self, ids ): """将token IDs解码为文本""" return self .enc.decode(ids)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 train_dataset = MyDataset('' ) train_dataset, val_dataset = torch.utils.data.random_split(train_dataset, [0.9 , 0.1 ]) train_loader = DataLoader(train_dataset, batch_size=12 , shuffle=True ) val_loader = DataLoader(val_dataset, batch_size=12 , shuffle=False )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 model = GPT(GPTConfig()) device = "cuda" if torch.cuda.is_available() else "cpu" model = model.to(device) total_params = sum (p.numel() for p in model.parameters()) print (f"Total parameters: {total_params / 1e6 } M" )optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4 ) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=1000 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def train (model, optimizer, scheduler, train_loader, val_loader, device ): model.train() total_loss = 0 for batch_idx, (x, y) in enumerate (train_loader): x, y = x.to(device), y.to(device) logits, loss = model(x, targets=y) optimizer.zero_grad() loss.backward() optimizer.step() scheduler.step() total_loss += loss.item() if batch_idx % 100 == 0 : print (f'Epoch: {epoch} , Batch: {batch_idx} , Loss: {loss.item():.4 f} ' ) return total_loss def eval (model, val_loader, device ): model.eval () val_loss = 0 with torch.no_grad(): for x, y in val_loader: x, y = x.to(device), y.to(device) logits, loss = model(x, targets=y) val_loss += loss.item() return val_loss for epoch in range (2 ): train_loss = train(model, optimizer, scheduler, train_loader, val_loader, device) val_loss = eval (model, val_loader, device) print (f'Epoch: {epoch} , Train Loss: {train_loss/len (train_loader):.4 f} , Val Loss: {val_loss/len (val_loader):.4 f} ' ) avg_val_loss = val_loss / len (val_loader) checkpoint = { 'epoch' : epoch, 'model_state_dict' : model.state_dict(), 'optimizer_state_dict' : optimizer.state_dict(), 'scheduler_state_dict' : scheduler.state_dict(), 'val_loss' : avg_val_loss, } torch.save(checkpoint, f'checkpoints/model_epoch_{epoch} .pt' )